映像とセンサー情報を組み合わせて学習することにより、判別しにくい行動の認識精度を最大53%向上できることを確認
2019年12月20日
株式会社日立製作所
日立は、映像内の人物の一部が遮蔽されたり、動きが微小で判別しにくい行動を認識可能な、人物行動認識AI技術を開発しました。本技術では、カメラの映像情報と複数種類の身体装着センサーから得られる信号情報を組み合わせてAIにあらかじめ学習させておくことで、カメラ映像のみからでもリアルタイムに微小な行動の変化を捉え、体の一部が遮蔽されていても人物の行動を高精度に認識することができます。今回、映像のみで学習した行動認識技術と比較したところ、これまで判別が難しかった行動の認識精度を最大53%向上できることを確認しました。これにより、人混みや植え込みの陰など見通しの悪い状況での不審行動や、工場作業者と機械との接触事故など、映像認識技術によって検知できる対象を広げることができます。今後、日立は本技術を映像監視システムに適用し、人々の安心・安全の向上や工場の安全業務への支援拡大などに貢献していきます。
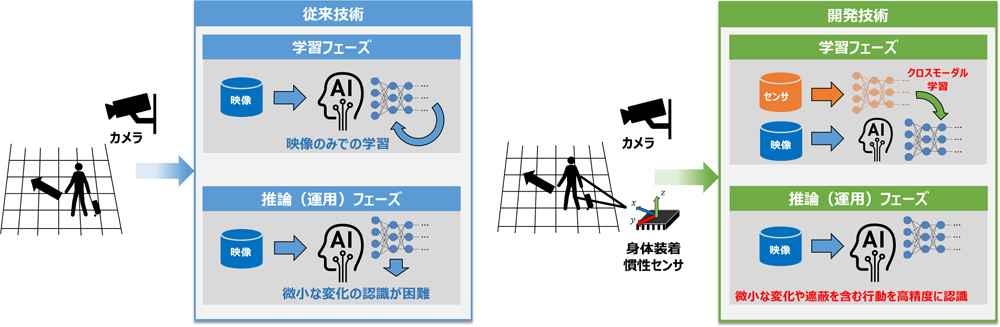
図1 従来技術と開発技術との違い

図2 公開するデータセットから一部行動のサンプル画像

図3 開発したクロスモーダル認識技術の詳細
判別したい行動毎に、どこの身体部位のセンサー情報が認識に有利となるかは異なります。センサー情報を映像による認識の学習に反映させる際に、教師情報として無差別に学習させてしまうと、行動の認識に不利なセンサー情報も学習してしまう恐れがあります。今回、行動別に認識に有効な部位のセンサー情報を動的に選別できるアテンション構造*1を開発したことで、効果的にセンサーからの行動情報を、映像モデルの学習に利用できるようになりました。
本技術では、センサーと映像など異なる種類の情報を組み合わせてAIに学習させることを可能としました。本方式では、知識蒸留*2と呼ばれる、教師モデルからの情報を生徒モデルに学習させる方式を応用しています。教師モデルは、センサー情報から自動的に選別された学習情報と、映像中の行動に対する正解情報を対応づけて作成されます。生徒モデルは、映像のみから行動を識別するモデルとして作成され、入力映像に対する教師モデルの出力結果を正解情報として学習が行われます(クロスモーダル学習*3)。これによってセンサー情報を活用した、遮蔽に対し頑健で小さな行動変化に敏感な教師モデルの推論能力が生徒モデルに受け継がれます。本技術を映像監視システムに適用する場合、学習済みの学生モデルを用いることによって、センサーなしでカメラの映像のみから行動認識を行う方式でも、微小な行動変化を捉え、高精度な人物行動認識を行うことができます。
今回の研究成果では、センサーで映像を学習させましたが、逆に映像を教師として活用してセンサーのみの行動解析に利用したり、異なる画角間の映像情報を互いに利用し、画角変化にロバストな人物検知を行うなど、行動認識以外の分野へ活用することも可能と考えられます。
また、本技術のさらなる検証に向けて、今回日立が構築したセンサーと映像情報を有する大規模データセットを一般に公開しました*4。今後、本分野の研究を活性化させ、技術開発を協創できる環境を作るため、関連するイベントやワークショップを順次開催していく予定です。
関連リンク


