GPUを用いて全結合モデル向けのアルゴリズムを実装し、従来比250倍の高速化を実証
2019年8月30日
株式会社日立製作所
表1 さまざまな問題に対応可能なCMOSアニーリングのラインナップ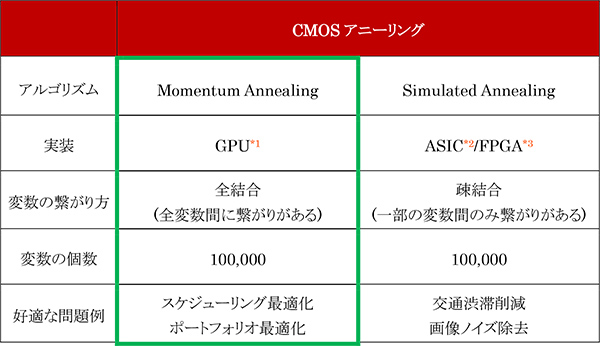
日立は、大規模なスケジューリング最適化やポートフォリオ最適化問題に対して、高速に実用解を探索する全結合モデル向けの最適化アルゴリズムを開発しました。本アルゴリズムをGPUで実装して、10万変数の組合せ最適化問題(全結合問題)*4を用いて検証したところ、従来アルゴリズム*5より250倍高速に近似解を求められることを確認しました。お客さまの課題に応じて、本アルゴリズムと日立がこれまで開発してきたCMOSアニーリングマシンを使い分けることで、幅広い実問題に対応できるようになります(表1)。今後、日立は、オープンな協創による新たなイノベーション創生を加速するための研究開発拠点として開設した「協創の森」*6を活用して、社内外のパートナーとともにソリューション協創を進め、複雑化する社会課題の解決に貢献していきます。
日立が提案するアルゴリズムはMomentum Annealing (MA)と呼ばれるもので、QUBO*7という組合せ最適化問題を解きます。MAは大域最適解を保持しつつ、すべての変数間に繋がりを持つQUBO (図1a)を完全二部グラフ状の繋がりを持つQUBO (図1b)に変換することを特徴とします。SAを代表とするマルコフ連鎖モンテカルロ法に基づく最適解探索アルゴリズムは、変数を逐次的かつ確率的に更新することで、大域最適解またはその近似解へ達することを期待します。マルコフ連鎖モンテカルロ法の理論的背景により、繋がりを持つ変数どうしは同時に更新できません。そのため、すべての変数間に繋がりを持つ全結合問題を解く場合は、一度に一つの変数しか更新できません。しかし変数間の繋がりが完全二部グラフ状の場合、図1bの左側の変数は互いに繋がりを持たないため同時に更新することが可能で、並列計算によって計算時間を短縮できます。右側の変数に対しても同様です。このような並列計算を活用することで、解探索を高速化します。
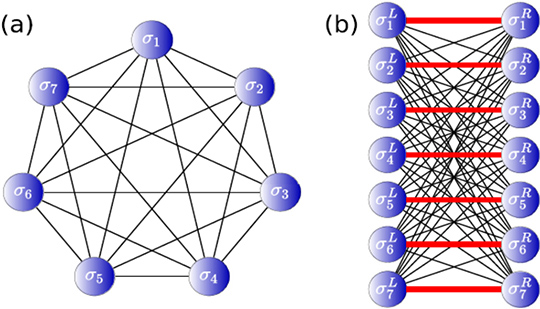
図1 変数間の繋がりの変換
MAでは、図1bの赤線で示す新たな繋がりを持つモデルを用いて解を探索します。この結合の影響が過度に大きい場合、局所解にトラップされ易くなり、さまざまな状態を探索して良質な解を求めるということが困難となります。一方で、結合が小さすぎる場合、本来解きたいQUBO(図1a)と、MAで扱うQUBO (図1b)の大域最適解が異なるものとなって適切ではありません。それぞれの問題の最適解が一致しつつ、新たに設ける繋がりをなるべく小さくすることが必要です。そこで変数間の繋がりを表す行列の最大固有値を用いる不等式を導出して、赤線の繋がりの大きさを適切に設定することで良質な解探索を可能としました。
これらを基に、全ての変数間に繋がりを持つQUBOの解探索を高速に実行する方法として、ディープラーニングに代表される科学技術計算で幅広く使用されているGPUを活用したプログラムを作成しました。単精度浮動小数で表現した変数間の繋がりを持つ10万変数のQUBOを扱うため、4台のNVIDIA Tesla P100*8でMAを実行して、IBM Power 8*9で実行したSAよりも、最適化アルゴリズムの一つであるSahni-Gonzales (SG)で得られた近似解と同等の解精度に到達するまでの計算時間が1/250になることを報告しました(図2)。
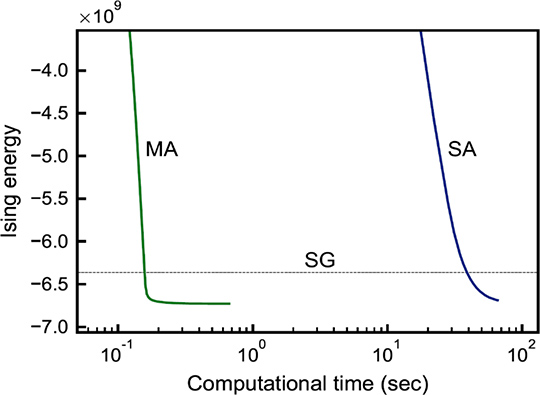
図2 10万スピン全結合イジングモデルの基底状態探索問題をSAに対して250倍高速化
横軸は実行時間、縦軸は組合せ最適化問題の目的関数値を表す。