物体識別のベンチマーク画像を用いた検証で最大7.54%の認識精度向上を実証
2019年9月2日
株式会社日立製作所
日立は、認識対象物の要素を分解することで、少ないデータでも高精度に学習することができる画像認識AI向けの深層学習技術を開発しました。従来では、認識対象物の特徴に加えて学習データに含まれる背景の特徴などを含めて学習していたため、背景画像が学習時と異なる場合の認識精度が低下していました。本技術では、認識対象物には直接関係しない背景などの特徴と、認識対象物の不変的な特徴を捉えることができる形状や色などの特徴の要素に分解して学習し、かつ認識対象物の不変的な特徴を選別して認識することで精度を高めます。物体識別のベンチマーク画像を用いた検証を行い、従来手法に対して認識精度が最大7.54%向上することを確認しました。今後日立は、公共エリアでの映像監視や産業分野における目視検査代替など、十分な学習データを集めにくいとされる分野への適用を進め、社会の安心・安全や生産現場の効率化に貢献していきます。
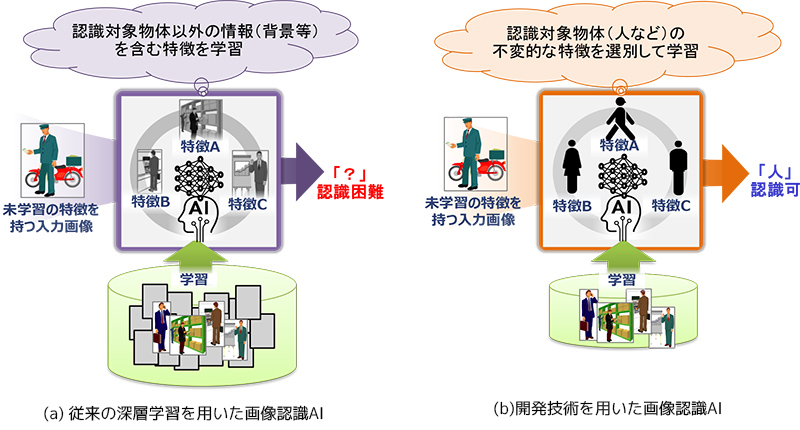
図1 従来技術と開発技術との違い (画像内の人を認識する場合のイメージ図)
従来の深層学習技術は、大量の学習用データを用いて、人や車などの認識対象物体の画像特徴量をニューラルネットワークに学習させておくことで、入力画像の画像特徴量を解析しながら物体認識を行う画像認識AIを生成します。日立は、このニューラルネットワークで学習した画像特徴量群について、認識対象物体とは直接関係しない背景情報などの画像特徴量と、認識対象物体の不変的な特徴を捉えることができる画像特徴量が混在していることに着目しました。本技術は、上記画像特徴量を要素分解しながらニューラルネットワークに学習させます。
本技術は、入力画像毎に要素分解した画像特徴量の中から、認識対象物体の不変的な特徴を捉えることができる画像特徴量を自動選別して物体認識を行います。これにより、未学習の画像特徴を有する物体の認識精度が向上し、画像認識AIの汎化性能*3が向上します。事前に十分な学習データを集められないケースにおいても、本技術を適用することで、高精度な画像認識AIの生成が可能となります。
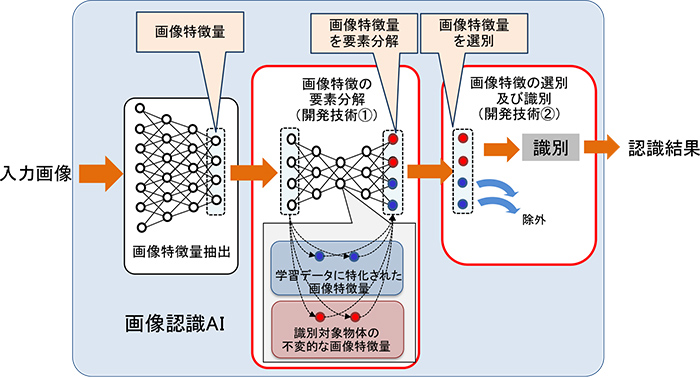
図2 今回の開発技術を活用した画像認識AIの詳細
関連リンク


