
ストレージについての解説の途中でピーちゃんに置いてけぼりにされてしまった国府津さん。
トラブルの原因を突き止めることはできたのでしょうか…。
――――次の日の朝

ぜぇぜぇ…
どうやらサーバAとサーバBがMPブレードを共有していたことで、I/O負荷が集中していたことが原因みたいだ。MPブレードを分けて処理させることで対処したけど…
あぁ、もう夜が明けている…

グッモーニン! よく頑張りましたね、ナイス ファイトでございました!

あ、戻ってきてくれたんだね、ピーちゃん!
昨日の続きをお願いします!

ええ、もちろん! あなたのガッツにエモーションしました
ここからは、ピーちゃんがエクスプレインいたします!
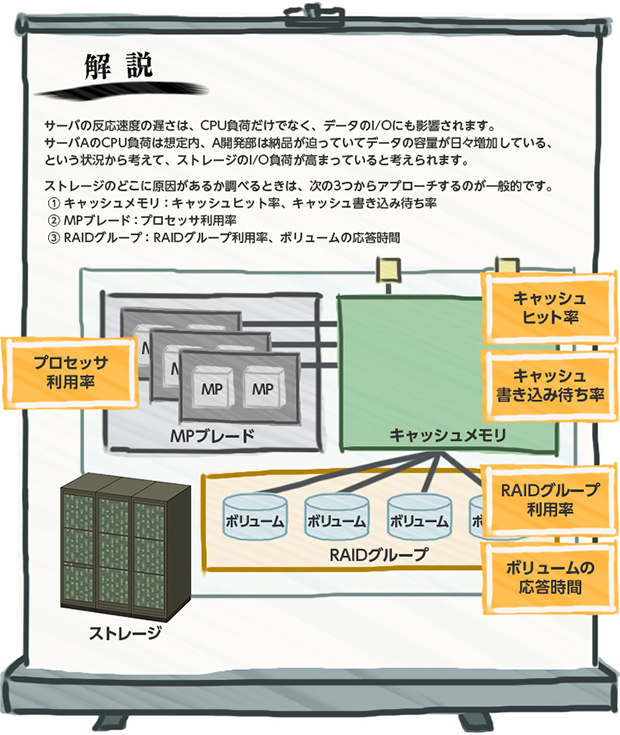

今回はMPブレードの負荷が増えた、ということがわかりましたが、キャッシュメモリや、RAIDグループが原因の場合もあるんです。
キャッシュメモリ、MPブレード、RAIDグループの3つは定期的に確認することをレコメンドしますよ。
ドゥ ユー アンダスタン?
イエス、アイ アンダースタンド! サンキュー、ベリーマッチ!!
キャッシュメモリ、MPブレード、RAIDグループの定期的なチェックか…、簡単にできる方法があればいいのになー
それはですね…
下の記事をリーディングしてみてください!
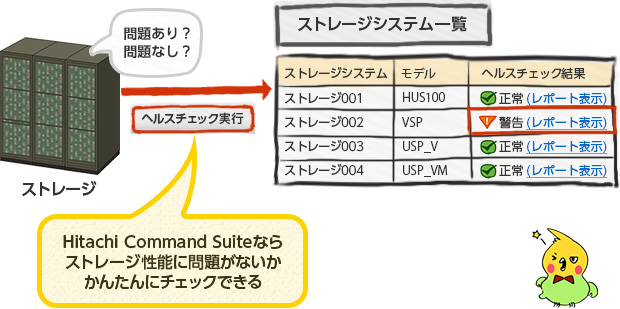
今回のお題では、サーバの応答性能にストレージのI/O負荷のひっ迫が影響している、というものでしたが、ストレージの調査はなかなか難しいものです。
しかし、Hitachi Command Suiteの「ヘルスチェック」を使えば、ストレージの性能に問題がないかどうかをかんたんにチェックできます。日立が長年培った運用ノウハウに基づいて、リソースの状態を「正常」、「注意」、「警告」で自動判定できます。
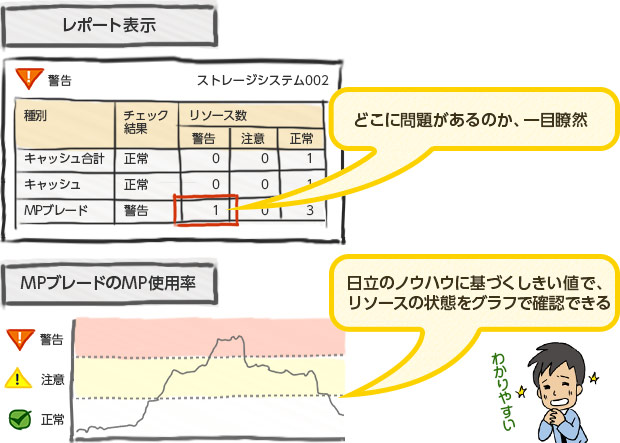
ヘルスチェックレポートは、ストレージ内部のリソースのどこに原因があるのか一目瞭然。MPブレードのMP使用率などを、グラフ形式で時系列に見ることもできます。
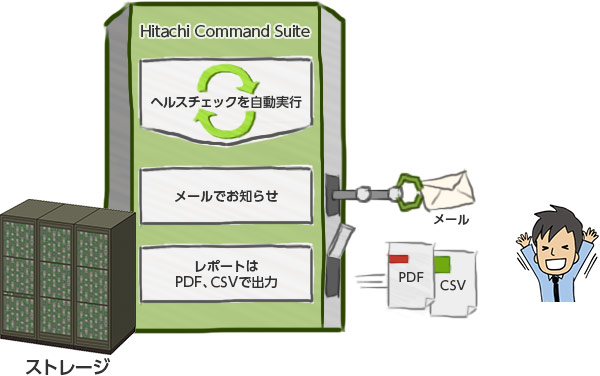
PDFやCSVファイルでヘルスチェックレポートを出力したり、ヘルスチェックをスケジューリングして自動実行することもできます。自動チェックの結果は、Hitachi Command Suiteからあなたにメールで届きますので、ストレージの状況を定期的に確認、把握することができます。

Hitachi Command Suiteを使えば、ストレージの管理がとっても効率的になるんですね!!
すばらしーい
ザッツ ライト、です!
ヘルスチェックレポートのPDF、CSV出力は、Hitachi Command Suiteを利用中のお客さまからもご好評いただいています!








