本ページ内の製品画像はPentahoのバージョンがV8の製品画像となります。
記載の仕様は、製品の改良などのため予告なく変更することがあります。
データ統合基盤は、ビッグデータの分析や利活用に必要不可欠なETL*ツールです。
クライアントツールのグラフィカルな環境で開発したETL処理を、Pentahoサーバーにアップロードして、本番実行します。
クライアントツールで開発・デバッグ・プレビューが完結するため、効率良くETL処理を開発できます。

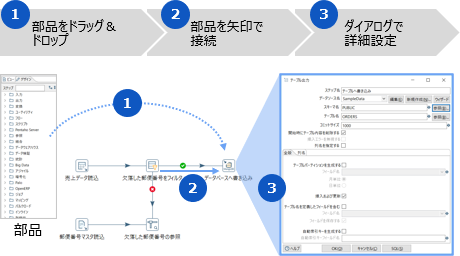
PDIのクライアントツールでは、データ取り込みや加工などのETLを構成するさまざまな部品が提供されています。
これらをドラッグ&ドロップで配置し、処理の流れに合わせて矢印でつなぐことで、ETL処理を視覚的に定義できます。
GUIを使ってプログラミングレスで開発できるため、ビジネス部門のユーザーの方でも容易に利用できます。
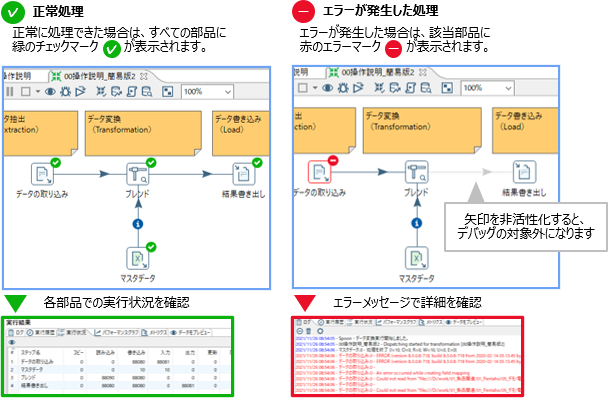
開発したETL処理は、クライアントツール上でデバッグできます。エラーが発生した部品をアイコンで特定し、メッセージを基に対処できます。
デバッグ時に処理の一部を実行したくない場合、矢印を非活性化すると、矢印の先の処理は実行されません。状況に合わせて、実行したい処理を選択・限定できるので、効率良く開発できます。
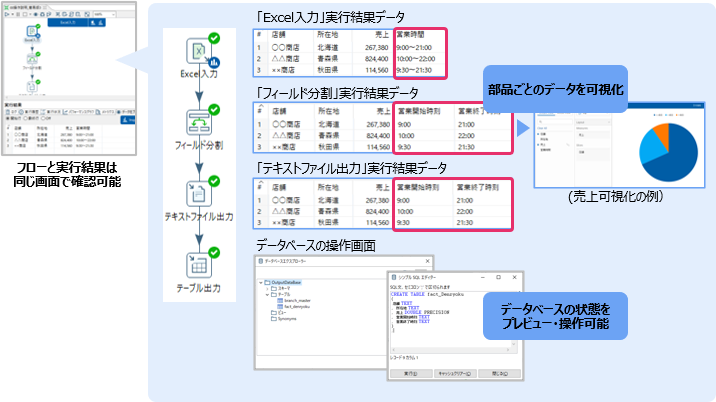
デバッグ実行した処理では、各部品の実行後のデータを部品ごとに確認できます。データの状態を細かく確認しながら開発することで、定義の誤りなどに早めに気づくことができます。
また、データベースに接続する処理では、クライアントツールの画面上で接続先のデータベースの状態をプレビューできます。SQLも実行できるため、簡単な操作であれば、専用ツールを使わずにデータベース操作を実行できます。
Pentahoでは、データの入出力、ソート、集計、重複削除、ジョインなど、さまざまな処理を実行するための部品が300種類以上用意されています。
個々の部品は細かい処理単位で用意されているため、組み合わせることで複雑・高度な処理も実現できます。
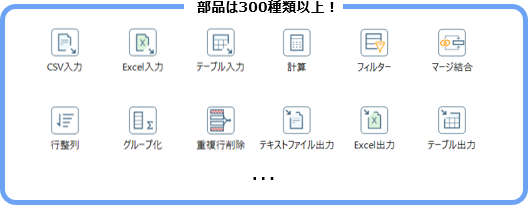
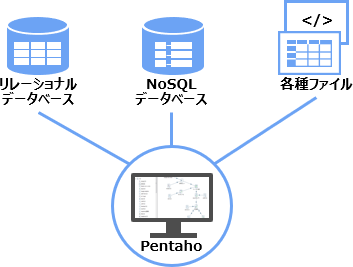
Pentahoでは、多種多様なデータ形式に対応しています。
また、AMQP (Advanced Message Queuing Protocol)やApache Kafkaなどのメッセージ連携技術と連携し、秒単位でのストリーミングデータ処理も可能です。
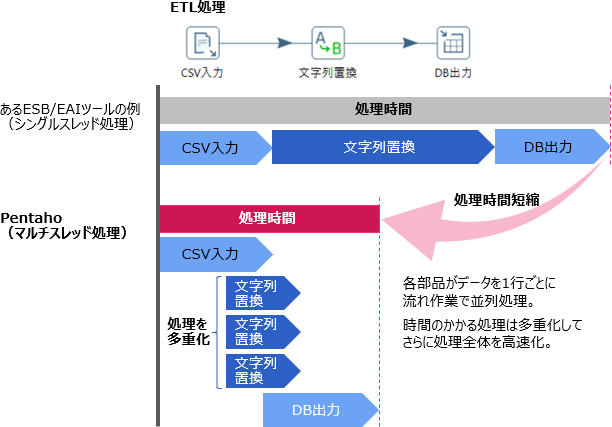
PentahoのETL処理では、各部品がデータを1行ごとに流れ作業で並列処理します。
各部品はマルチスレッドで実行されるため、マシンリソースを効率的に利用し、部品ごとにシングルスレッドで処理する場合と比べて、大量データを高速に処理できます。
時間がかかる特定の処理がある場合、その処理を多重化してCPUリソースを多く割くことで、さらに処理を高速化できます。
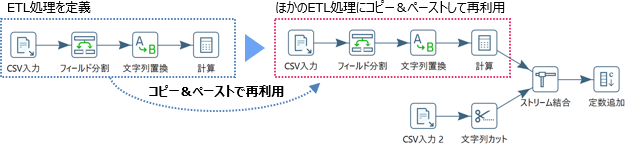
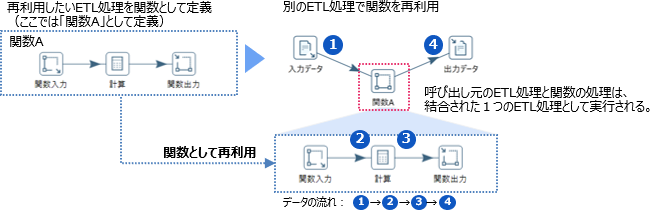
クライアントツール上では、ETL処理の全体または一部をコピーして、ほかのETL処理で再利用できます。
また、よく使われるETL処理を関数化して、ほかのETL処理から呼び出すこともできます。
一度定義したETL処理を再利用することで、効率の良い開発ができます。
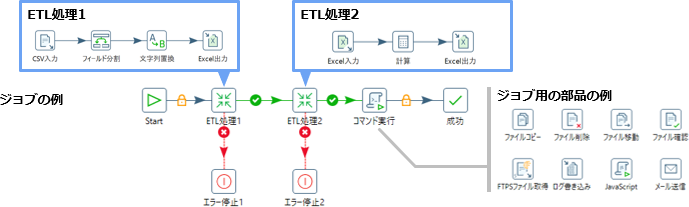
複数のプロセスをジョブとしてフロー化し、順序関係を制御できます。ジョブは、ETL処理と同様に直観的な操作で作成できます。
ジョブの作成では、Pentahoで用意されているジョブ用の処理の部品と、個別に開発したETL処理とを組み合わせて使用できます。
コマンドラインで任意の処理を実行する部品を使用することで、外部ツールとも連携できます。
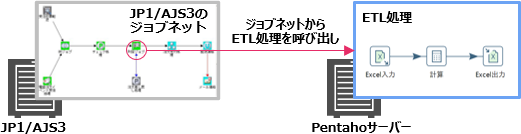
また、Pentahoのジョブ管理よりもさらに細やかにスケジューリング・エラーハンドリングなどの制御をしたい場合は、JP1/AJS3*などの運用管理ツールからETL処理を制御できます。JP1/AJS3のジョブネットからは、コマンドラインでPentahoサーバー上のETL処理を呼び出せます。
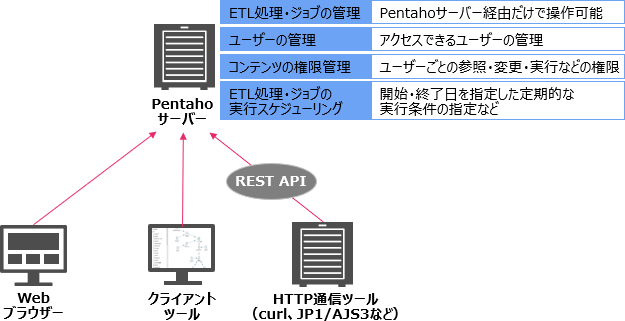
Pentahoサーバーでは、主にETL処理・ジョブの管理、ユーザーの管理、コンテンツの権限管理、ETL処理ジョブの実行スケジューリングを実施します。
Pentahoサーバーは、Webブラウザー、ETL開発用のクライアントツール、REST APIなどから操作できます。
AWS S3などクラウドストレージと連携するための部品があり、Amazon S3、Google Cloud Storageなどのクラウドストレージサービスと容易に連携できます。また、Parquetなどのビッグデータ用のファイル形式にも対応しています。
AWSやAzureなどのパブリッククラウド上の仮想サーバーに、Pentahoをインストールできます(前提OSがインストールされていることが必要です)。また、SnowflakeやAWS Redshiftなど各種クラウドデータベースなどにも容易に連携できます。そのほか、JDBCやREST APIなとどいった汎用的なインターフェースによって、多くのサービスと連携できます。
Pentahoは、Pythonと連携するための部品を用意しています。これにより、Pythonによる生成AI・機械学習のロジックをPentahoのETL処理に組み込めます。
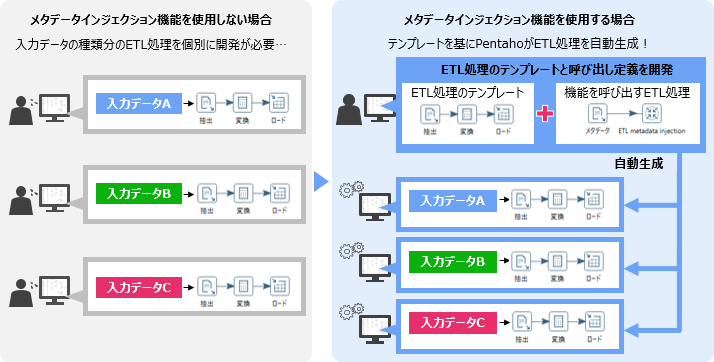
データの加工内容が同じ、かつ複数種類の入力データのETL処理を開発する場合、一般的なETLツールでは、入力データの種類ごとにETL処理を開発する必要があります。
Pentahoのメタデータインジェクション機能を使用すると、ETL処理のテンプレートとメタデータインジェクション機能を呼び出すETL処理の2つを開発するだけで、以降、入力データに応じたETL処理を自動作成できます。入力データが増減した場合も、ETL処理の追加・削除は不要です。
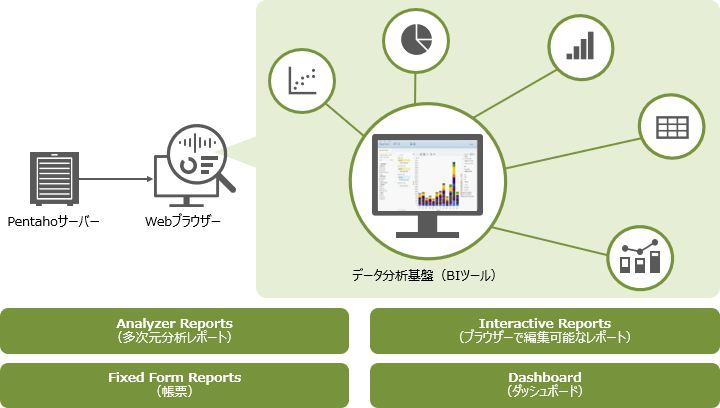
Pentahoのデータ分析基盤(PBA)は、データ分析におけるデータの可視化を目的としたBIツールです。
PBAでは、データを4つの形式で可視化します。ビジネス部門のユーザーはPentahoのサーバーにアクセスすることで、Webブラウザー上でレポートやダッシュボードの閲覧、操作、および作成ができます。
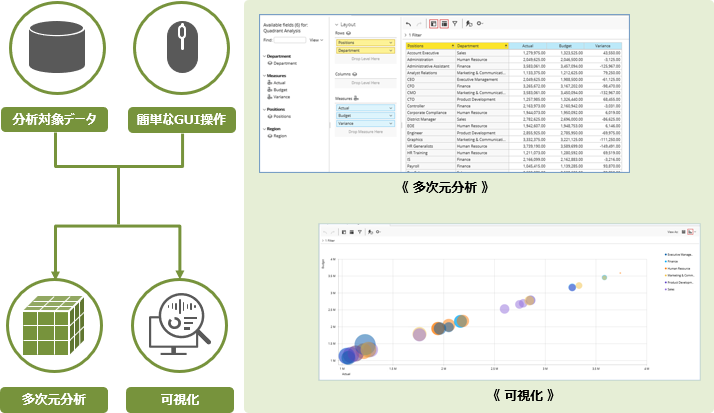
Analyzer Reportsでは、データ項目を多次元分析(OLAP分析)できます。
ブラウザー上での、ドラッグ&ドロップなどの直観的な操作のため、分析軸のドリルダウン、スライス、ダイスなどの操作や、データのグラフ化も容易です。
Interactive Reportsでは、ブラウザー上でのGUI操作で帳票形式のレポートを作成、閲覧できます。
インタラクティブな項目の追加、フィルタ条件の変更などが可能です。

Fixed Form Reportsでは、専用のクライアントツールで帳票形式のレポートを作成できます。
Interactive Reportsよりも表現のバリエーションが多く、詳細にレイアウトを調整できます。

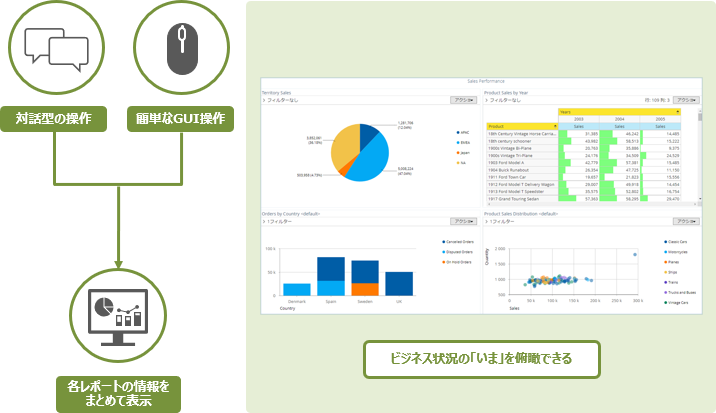
Dashboardでは、各種レポートの情報をまとめて表示することで、ビジネス状況の「いま」を俯瞰的に参照できます。
ドラッグ&ドロップなどの直観的な操作で自由にレポートを配置、分析対象を対話的な操作で指定します。
また、ドロップダウンなどの作成により、ユーザーがフィルタ条件をインタラクティブに変更して閲覧できます。
データ統合基盤(ETLツール)とデータ分析基盤(BIツール)は次のように連携できます。