ビッグデータでビジネスを成功に導くには:
今日、データのオンボーディング(オフライン情報のデジタル化)をするために、何百ものデータソースをHadoopへ収集するプロセスを実装したり、ビジネスユーザーがIT部門に頼らずにデータをアップロードする仕掛けを開発したりしている企業も多いでしょう。しかし、いずれのやり方の場合でも、手作業の設計の繰り返しとそれに伴う開発時間の増加、さらに手動が故のエラー発生リスクといった問題が発生しがちです。
大規模データのオンボーディングのアプローチを簡素化することにより、ビッグデータ収集の煩雑さを解消します。Pentahoを活用すると、わずか数回の変換で何百種類ものデータの収集、および準備処理を実行できるため、開発時間とリスクを減らしつつ、すばやく分析情報を取得できるようになります。
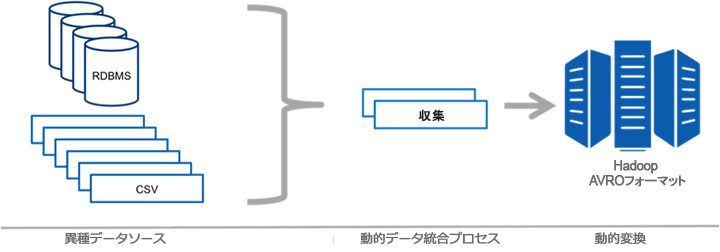
大量のソースを保持している企業にとって、多種多様なデータソースを定期的にHadoopに収集することは、非常に厄介で骨の折れる作業になります。Pentahoのメタデータ・インジェクション機能を活用すれば、高度な統合プロセスを通してデータのオンボーディング作業を効率的に行うことができます。
Pentahoのメタデータ・インジェクション機能を使用して、効率化された動的なデータ統合プロセスにより数千ものデータソースをHadoopに移動しています。