ビッグデータ時代のデータ分析で、成功・失敗をわけるものは何か。
![]()
データ分析がうまくいかないという人たちの話を俯瞰(ふかん)してみると、データ分析の前の準備段階でつまずいているケースが多い。
「いろいろな軸で分析したいけど、社内のデータが整理されていないので、分析に必要なデータがうまく集められない。」「分析したいデータの形式がバラバラなので、変換して共通の形式にそろえるのに非常に手間がかかる。」という声が多いからだ。
データ分析の前提として、非常に重要なファクターとなるのがデータの下準備である。
下準備とは、「データを収集する」「データを変換・統合する」「いろいろなデータをブレンディング(掛け合わせ)する」という作業のことで、これを経て分析に有用なデータが作られる。こうした分析用のデータが準備できていなければ、いくら分析ツールや機械学習、人工知能といった仕組みが整備されていても、有益な分析をするのは難しい。しかし、データの下準備が十分にできていない企業が非常に多いという現実がある。
なぜ失敗するのか
つまり、データの下準備ができていない企業は、「データを収集する」「データを変換・統合する」「いろいろなデータをブレンディングする」のどこかでつまずいてしまっているのである。
これは、主にビッグデータを管理する仕組みが整っていない場合が多い。音声や映像などの非構造化データや、センサーデータ、ログデータといった半構造化データを格納するのは簡単ではないため、その環境自体が整備されていないことが多いのだ。企業内にはあらゆるビッグデータが存在するのに、有効活用されずにデータが破棄されてしまっているのである。
これは、データのサイロ化が関係している。長い年月、企業のシステムは部門ごとに個別最適で構築されてきた。それぞれのシステムは分断・孤立していて、扱っているデータの形式や定義も異なるため、統合する前の変換作業が困難になっている。また、企業に散在するデータソースに対して、どこに何のデータがあるのか把握できていないという問題もあり、統合するための設計も非常に困難になっている現実がある。
これは、構造化データと非構造化データ・半構造化データをブレンドする仕組みがわからない、手作業でブレンドするので時間が掛かり過ぎる、そもそもビッグデータが格納できていないのでブレンドできない、といったことが理由になっている。
こうした課題を抱えているため、データの下準備がうまくできないのだ。しかし、データ分析を成功させている企業とは、データの下準備を制している企業である。ここで立ち止まっていては、優れた分析はできない。つまり、市場競争で優位性を得るチャンスを失う、ということを忘れてはいけない。
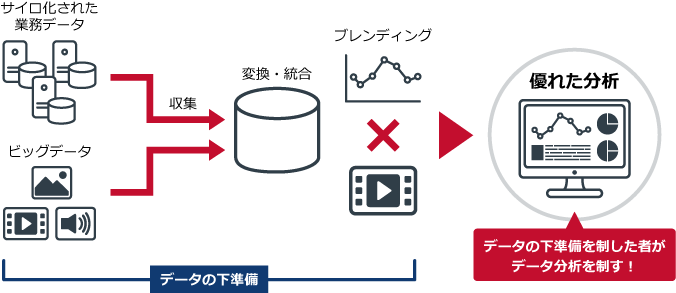
図:データの下準備を制した者がデータ分析を制す
データパイプラインは、優れたデータ分析を可能とする理想的な構想である。しかし、見よう見まねで構築しても決して成功はしない。次の3つの条件を満たしたデータパイプラインを構築することが、データ分析の成功へとつながる。
