
このニュースリリース記載の情報(製品価格、製品仕様、サービスの内容、発売日、お問い合わせ先、URL等)は、発表日現在の情報です。予告なしに変更され、検索日と情報が異なる可能性もありますので、あらかじめご了承ください。なお、最新のお問い合わせ先は、お問い合わせ一覧をご覧下さい。
2011年9月27日
株式会社日立製作所
国立遺伝学研究所
約5分の1のコストで従来システムと同等の処理性能を実現
株式会社日立製作所(執行役社長 : 中西 宏明/以下、日立)は、大学共同利用機関法人 情報・システム研究機構 国立遺伝学研究所(所長 : 小原 雄治/以下、遺伝研)五條堀孝教授グループの協力のもと、このたび、Hadoop*1技術を用いた大量ゲノムデータの分散処理環境を試作し、その有用性の検証を行いました。その結果、従来の分散処理システムと比較し、約5分の1のコストで同等のデータ処理能力が実現できました。
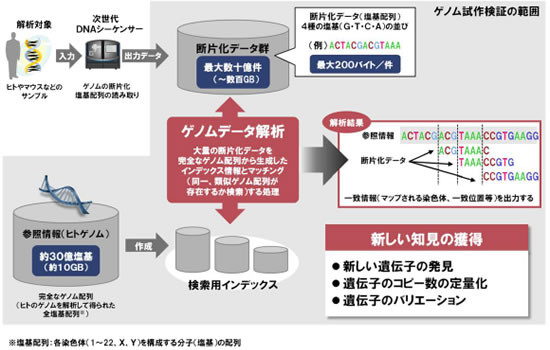
現在、ゲノム研究分野では、次世代DNAシーケンサー*2の発展が著しく、ヒトゲノムをはじめとした各種生物のゲノム情報の網羅的解析が加速しています。最新の次世代DNAシーケンサーでは、断片配列データと呼ばれるDNAの配列を解析単位に断片化したデータが、一回の計測で約60億個(約1.8TB)も生成されます。この次世代DNAシーケンサーの登場により、世界中の研究機関で生成される断片配列データ量は爆発的に増加しており、2010年に生成された塩基配列*3の断片データ量はPB(ペタバイト)*4オーダーに及びます。一方で、データ量の増大に比例してデータ解析にかかる時間が増大しており、研究のスピード化を妨げる要因の一つとなっています。このため、データ解析にかけるコストを大きく増やすことなく、解析スピードを向上させる大量データ処理システムの開発が求められています。
遺伝研は、現在、文部科学省「革新的細胞解析研究プログラム(セルイノベーション)」に参画し、次世代シーケンサーから産出される大量のゲノム関連情報を扱う解析拠点の整備を進めています。今回、日立は、ゲノムデータ解析の国内中核拠点である遺伝研の協力のもと、現在と同等のコストで飛躍的に解析スピードを向上させるための方策としてHadoopに着目し、検証を行いました。検証の内容としては、現在遺伝研が使用しているゲノム解析フローを、日立が構築したHadoop検証環境に移植し、さまざまな条件設定のもとゲノム解析を実行し、遺伝研でのゲノムデータ解析環境との処理性能の比較を行いました。この結果、従来システムと比較した場合、約5分の1のコストで同等のデータ処理性能が実現できました。これにより、今回の検証で構築したシステムを実用化した場合、従来システムと同等のコストで約5倍の処理性能が実現できることになり、研究機関はゲノム解析のスピードを大きく向上させることが可能となります。
なお、今回の検証環境の構築にあたっては、Hadoopの特長であるスケールアウト*5に適した、コストパフォーマンスに優れ、省スペースかつ省電力なサーバブレードを多数集約可能な日立のエントリーブレードサーバ「HA8000-bd/BD10」を用いました。また、ゲノム解析プログラムはSanger研究所開発の「Burrows-Wheeler Aligner(BWA) 」を用いています。
今後、日立は、ゲノム解析プログラムの選定をはじめ、それらをHadoop上で効率的に動かすための最適なシステム構成を実現するなど、今回の検証で得た知見と、ゲノム研究分野へ最先端の解析環境整備を行ってきたこれまでのノウハウをもとに、Hadoopを適用した大規模データ分散処理ソリューションの事業化をすすめ、ゲノム研究に注力する大学、研究所、製薬業界、食品業界などに提供していきます。さらに、そのほかの分野においても、大量データ活用に関してコンサルテーションからシステム構築までシステムライフサイクル全般におけるサービスを、株式会社日立コンサルティングをはじめ、日立グループ全体で充実させていきます。
また遺伝研は、より高速で効率的に収集・解析可能な大規模データ解析基盤の構築に取り組んでいきます。
国立遺伝学研究所(静岡県 三島市)は生命科学分野における遺伝学の中核拠点として、細胞機能・発生・分化・進化・生物多様性・ゲノム情報などについて、国際水準の先端的研究を行っています。また、知的基盤整備として、生命科学を先導するデータベース、バイオリソース事業を進めています。
日立では、大量データを活用したお客さまの新たなビジネスの開拓に向けて、Hadoopやバッチジョブ分散処理、ストリームデータ処理などの並列処理技術の適用性を判断するアセスメントサービスを提供しているほか、システム構築に必要な製品・サービス群を提供し、大量データ分散処理システムの構築を総合的に支援しています。
株式会社日立製作所 情報・通信システム社 公共システム営業統括本部
カスタマ・リレーションズセンタ [担当 : 佐々木、米山]
〒136-8632 東京都江東区新砂一丁目6番27号 新砂プラザ
以上