いま、データ分析業務では分析処理の高速化が求められています。しかし、近年はCPUが処理の負荷に耐えられないケースが増え、高速化の新たな壁になっています。
そこで日立では、ストレージチームとデータベースチームがタッグを組み、CPUの負荷を減らすための新しいデータ処理技術を開発。お客さまとの協創を通して、さらなる技術向上を図っています。

渡辺 聡(わたなべ さとる)
主任研究員

藤本 和久(ふじもと かずひさ)
主管研究員
(2017年2月14日 公開)
渡辺そうですね。これまでは、データ分析というと専門家が行うものというイメージがあったと思うのですが、そこが大きく変わってきています。いまは、専門家に限らずだれでも気軽に分析できる「セルフサービスBI」が必要とされています。例えば、保険会社の営業さんがお客さまと会話しながら、その場でBIツールを使ってリアルタイムでお客さま情報を分析し、最適な保険をご提案する、といった使い方が求められています。分析の活用の幅が広がっているんですね。こうなってくると、高い頻度で多くのユーザーがデータにアクセスするようになるので、システムの計算処理の性能を向上してほしいというニーズも高くなります。
藤本ビッグデータという潮流もありますし、処理性能の向上、特にデータ処理の高速化に対する期待は高まる一方ですね。これまでは、処理のボトルネックがストレージやデータベースにあったので、そこを解消するためのさまざまな取り組みが行われていました。例えば、ストレージはフラッシュメモリを搭載することで処理速度が100倍近く速くなり、データベースはカラムストア型を導入することで性能が大幅に向上しました。このようにストレージとデータベースの性能は改善されたのですが、今度は逆にデータの計算処理を行うCPUがその速度に追いつけない、という事態が起こってきてしまったのです。
図1 データ分析における処理ボトルネックの変化
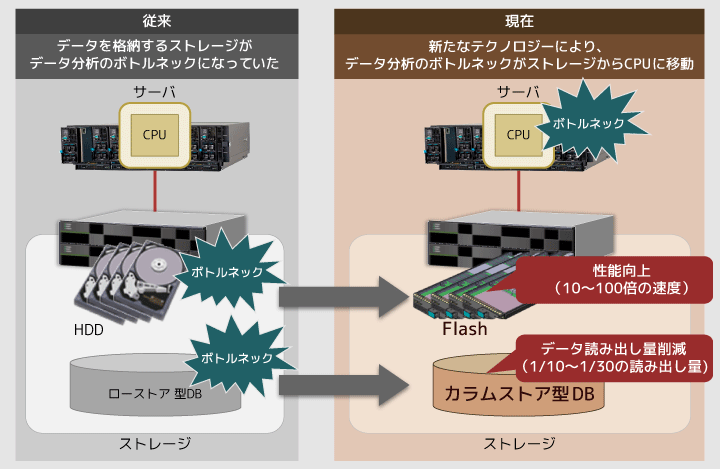
渡辺そうなんです。ビッグデータ処理と聞くと、インメモリデータベースというキーワードも出てくると思うのですが、結局CPUで処理をするので性能は変わりません。そういうわけで、CPUの演算処理をオフロードできるような新しい仕組みを考える必要がありました。
藤本特定の機能や処理性能を向上させるためのハードウェアやソフトウェアを「アクセラレータ」と呼ぶのですが、今回はCPUの演算処理をオフロードして高速化できるハードウェアアクセラレータを開発しようということになりました。もともと、ストレージ、データベースそれぞれを対象にCPUの負荷を減らすための研究を進めていたこともあって、タッグを組んで研究開発することになりました。
渡辺これまでの分析では、分析に使わないデータも含めてすべてのデータをCPUに処理させていました。データ量が膨大になり、データへのアクセス頻度が上がってくれば、CPUに負荷が掛かり、処理しきれなくなるのは当然です。そこで、「CPUが処理するデータ量を減らそう」という構想の下、お互いの研究成果を持ち寄って、研究開発の方向性を議論するところから始めました。

藤本もともとの専門分野が異なることから、最初の1年は議論がかみ合わないことが多くありました。でも、お互いに意見を出し合い議論しきったことで、そのあとの開発はうまく連携をとって進めることができました。
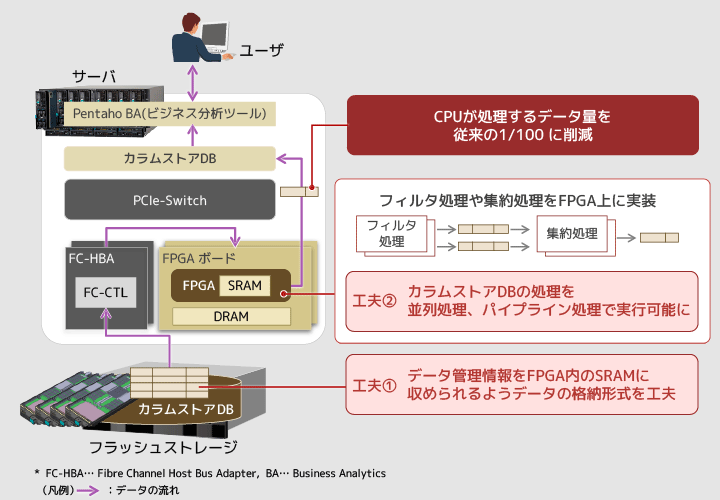
今回の研究では、CPUに渡すデータ量を減らすために、最低限のデータ処理を事前に実施できる仕組みを検討しました。具体的には、データ分析で頻繁に使う「フィルタリング処理」と「集約処理」をFPGAで実施してからCPUに処理結果を転送することで、CPUで実施する処理を軽くしたのです。このときに必要になってくるのが、ストレージからFPGAボードに直接データ転送する技術です。この部分の開発をわたしたちストレージチームが担当しました。ユーザー側からの分析の要求から、どのようにFPGAに指示を出すか。ストレージとFPGA間、FPGAとCPU間、それぞれどのようにデータのやり取りをさせればよいのか…。いままでなかった技術なので、悩むところも多かったですね。
渡辺わたしたちデータベースチームでは、カラムストア型のデータベースをFPGAに対応させるための技術を開発しました。従来のローストア型データベースとFPGAの組み合わせなら前例があったんですが、カラムストア型はなくて…。データの並び方、データの持ち方、処理方式、どれも大きく変わるので大変でしたね。さらに、求められる処理速度をクリアできるよう、データベース内のデータの格納方法や処理方式を工夫しています。

渡辺一つ目がデータのフォーマット、格納形式です。カラムストア型の場合、データの圧縮ルールや格納位置などを管理するために、データそのもの以外に「データ管理情報」を持っています。このデータ管理情報はデータの場所を示す辞書のようなものなので、データにアクセスするときは必ず参照します。CPUの負荷を減らし、処理を高速化させるためには、データ管理情報もFPGA上に持ってきて処理する必要があります。しかし、普通の格納方式だとFPGAのメモリよりもデータ管理情報の方が大きくなってしまう…。ですので、FPGAのサイズに収まる辞書になるよう、データを細分化して格納するようにしています。
そして、二つ目がFPGAで行うデータベース処理の高速化です。FPGAで実行する処理を高速化する手法としては、並列処理とパイプライン処理があるのですが、カラムストア型のデータベースではデータの並び順の問題からこれらの手法の適用が難しい。そこで、フィルタリング処理はカラム形式で処理し、集約処理はカラム形式をロー形式に再構成して処理する工夫をして、高速化を図りました。
藤本実はハードウェアにデータベース処理をオフロードする技術自体は30年ぐらい前からあったんです。でも、CPUの技術向上の方が進んでいてあまり日の目を見なくて…。今回は、その技術をリバイバルして、カラムストア型に適用させました。並列処理やパイプライン処理の使いどころも工夫したことで、従来の100倍の速さで処理できるようになりました。ストレージもデータベースも、多くの点で悩まされた開発だったので、苦労した甲斐がありましたね。
図2 FPGAを活用したデータ処理技術の概要
藤本はい、研究の成果を早めに社外に発表し、お客さまの意見を聞きながら製品を作るスタイルで研究開発に取り組んでいます。製品化前に発表することで、お客さまのニーズがどこにあるのを事前に把握して、製品に反映することができます。ソフトウェア開発ではすでに取り入れられている手法なんですが、今回のようなハードを含めた製品開発にこのような手法を取り入れるのは珍しいケースだと思います。

渡辺研究というのは、お客さまに興味を持っていただくことが重要だと考えています。興味を持っていただければ、そこから会話が始まり、さまざまなアイデアをいただくこともできます。自分たちだけでやっているとどうしても独りよがりになってしまうこともあるので、今回のような活動はとても有益だと感じています。
今回、北米での展示会やニュースリリースの公開などを通して、国内外から多数のお問い合わせをいただきました。当初の狙い通り、金融や通信、eコマースなど大きなデータを扱っているお客さまからの反応が多いですね。さらに、一部のお客さまからは実際にデータをいただき、実証実験というかたちでこの技術の有効性を検証している最中です。
渡辺そうですね。今後はお客さまの意見を踏まえつつ、日立の超高速データベースエンジンHitachi Advanced Data Binderプラットフォームへの導入をめざしていきます。
藤本お客さまからは、もっと高速化してほしいというニーズやほかの処理もオフロードしたいというニーズがあります。FPGAに入れられるロジックには制限があるのでなかなか難しいのですが、最新のデバイスを活用することも視野に入れつつ、お客さまのご要望に応えられるような製品にしていきたいです。

藤本今回の経験を通して、早い段階で技術をオープンにして、お客さまと一緒に作り上げていくというやり方は、今後ますます重要になってくるのではないかと身に染みて感じました。自分たちにも変化が必要だと強く感じています。特に、開発スピードについてはこれまで以上にスピード感を持たないといけません。要望をいただいてから、いかに早くものを見せられるかが勝負になるからです。やりがいがある分、自分たちも変わっていかなければならないし、どんどんチャレンジしていかなければいけないと思います。
渡辺今回開発した、CPUの処理を高速化するアクセラレータは、いま盛り上がっているテクノロジーの一つです。今後も新しいメモリやストレージが出たり、新しいデータ処理方式が開発されたり、と技術の進展が予想されています。そういった世の中の流れを上手く活用して、そのときどきのニーズに合ったものを提供できるようにしていきたいですね。
それと、お客さまとやりとりする中で感じるのは、いままでにない新しい技術であることをアピールした方が興味を持っていただける、ということです。今回は「アクセラレータ」というキーワードで新しい技術であることを印象づけられたのがよかったんだと思います。今回の活動では良い形でお客さまとの関係を構築できたので、この良い流れを次につなげていきたいと思っています。



