コンセプト
データ抽出ソリューションは、「ダークデータ」*1と呼ばれる、企業内にある活用効率が悪いデータや蓄積されたまま未活用となっている非構造データを、高精度かつ効率的に解析し、ビジネスへの利活用を促進するソリューションです。
- *1
- 企業内で日々収集・蓄積されていくデータのうち、活用されていないデータ、または活用されているものの手間がかかり活用効率が悪いデータ。
概要
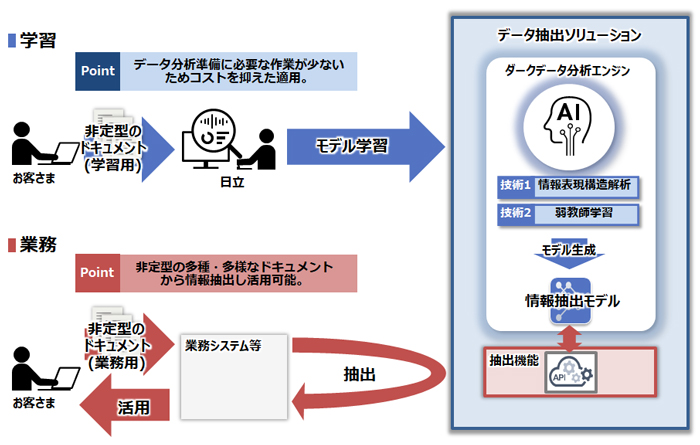
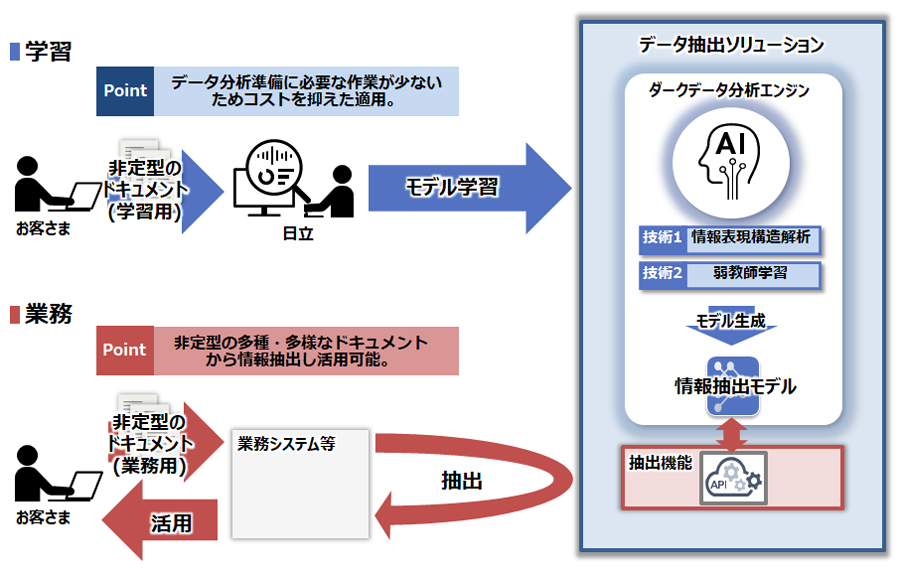
AIを活用したOCR技術の高度化により、フォーマットが定型または準定型なドキュメントからの情報抽出が可能になってきましたが、非定型ドキュメントからの情報抽出には対応できない事例も多く、多くの企業は今もなおドキュメントからの情報抽出・データ化に多くの人手をかけています。また、従来のAI技術ではデータ分析準備に多大なコストが発生する課題もありました。
本ソリューションでは、中核技術としてダークデータ分析エンジンを活用し、従来のAI技術では抽出が困難だった非定型の多種・多様なドキュメントから効率的に情報抽出が可能です。また、従来のAI技術よりもデータ分析の準備に必要な作業が少ないため、従来と比較して導入・運用コストを抑えた適用が可能となります。
本ソリューションは、これまで多くの人手での対応を余儀なくされていた業務の効率化を支援します。また、企業内で活用されてないドキュメント内のデータに意味を持たせることで、更なる分析につなげるなど、新しい価値の創出を支援します。
{kind=link}
特長
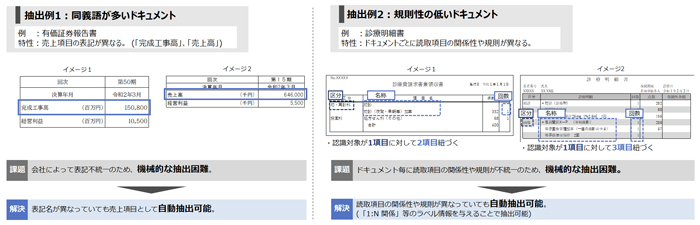
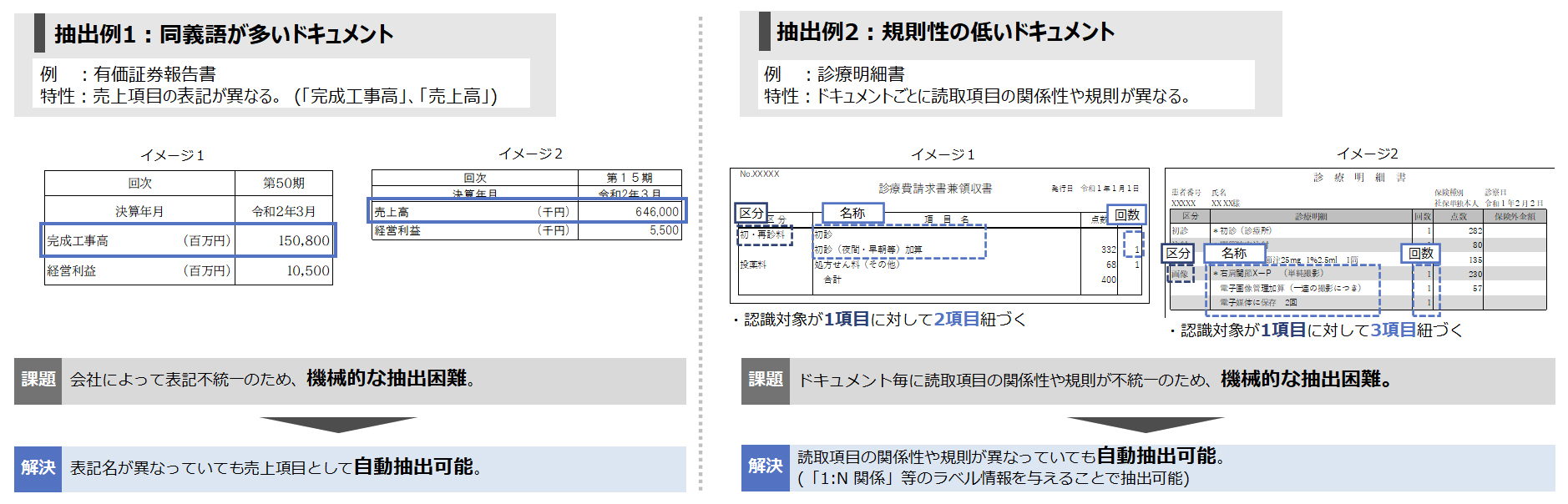
非定型の多種・多様なドキュメントから情報を抽出(技術1:情報表現構造解析)
この技術は、ドキュメントの様々な特徴(表、図、ページ情報、テキストの座標情報など)を活用します。
この技術を使うことで、今まで抽出困難であった非構造(情報表現の構造に関する仕様が定まらない)情報も抽出可能です。
(例:抽出したい対象の項目名にばらつきがある、項目名と値が1対多の構造など)
今までの技術では困難であった非定型ドキュメントからの情報抽出の自動化、業務効率の改善に寄与します。
{kind=link}
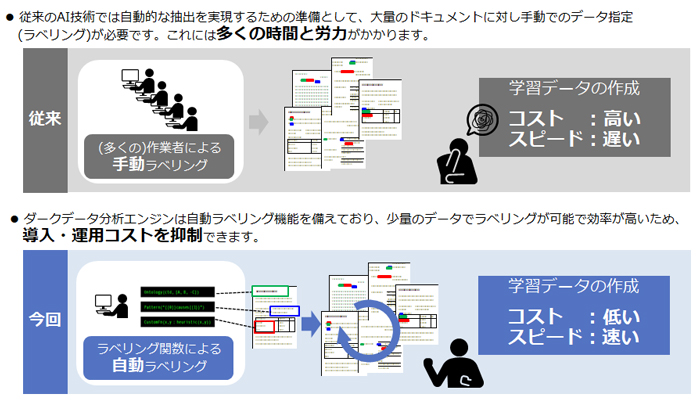
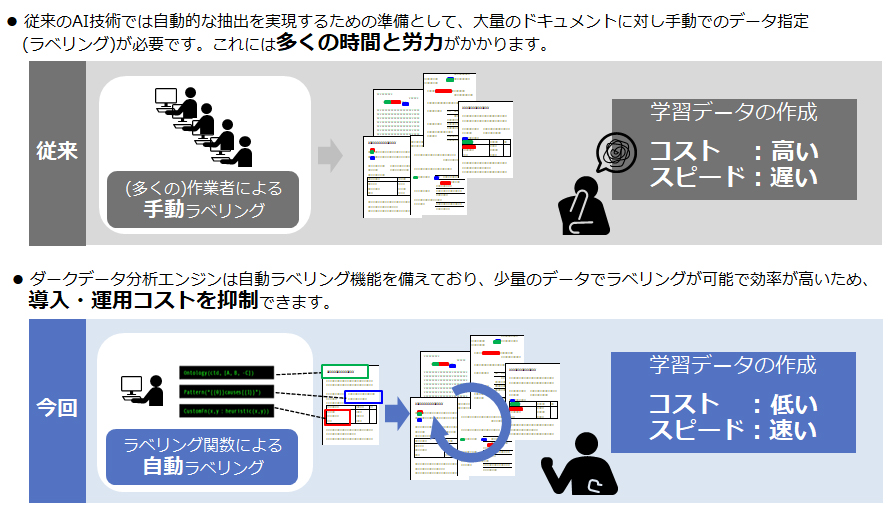
効率的なモデル構築と改善(技術2:弱教師学習)
この技術は、従来の学習データに対する人手によるデータ指定(手動ラベリング)に多大なコストがかかる「教師あり学習」と比較し、自動ラベリング機能の活用で、自動的な情報抽出を実現するために必要なモデルの効率的な構築および継続的な改善が可能です。
見直し時の追加学習、再学習時にも柔軟に対応でき、運用の効率化にも寄与します。
{kind=link}
サービスメニュー
サービス商品体系は、下記のとおりです。
| 名称 | 概要 | 価格 |
|---|---|---|
| データ抽出ソリューション | ダークデータ分析エンジンを活用し、非定型の多種・多様なドキュメントから情報を効率的に抽出することで、企業内に蓄積されている多様な情報の利活用を支援するソリューションです。 | 個別見積 |
関連情報
ニュースリリース
- 2021年6月23日