
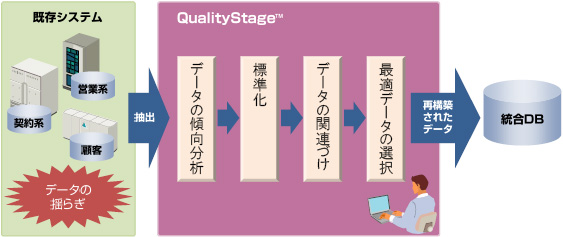
名寄せを行う際、その精度に多大な影響を及ぼすデータの揺らぎ。例えば住所データでは、カナ住所と漢字住所のほか、全角・半角や新旧漢字の混在、都道府県データの入力漏れ、番地やマンション名の入力の有無など、データの揺らぎは多岐にわたります。
名寄せツール「QualityStage」は、住所データや名前データの表記の揺らぎを解消し、顧客データの品質を上げる4つの機能を提供。各機能を利用しながら、DataStageの開発画面から効率的な名寄せジョブ開発が可能です。
単語の出現頻度やパターンなどのデータ傾向の分析を行います。
お客様のデータ品質を定量的に確認し、名寄せのためのキー項目として使用できるかを調べます。
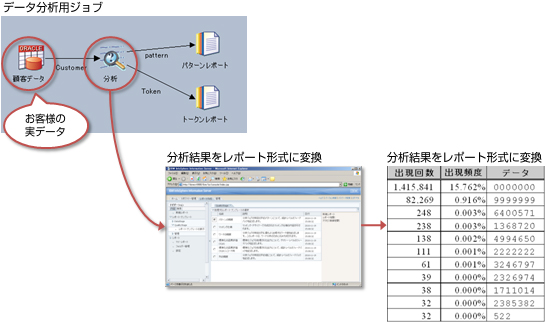
出現頻度/パターンの分析 − 調査からわかる内容(例)
データ構造やデータの揺らぎを吸収し、統一的な表記に変換します。
漢字の表記を統一したり、住所データを定型的なカテゴリに再配置することで、データを比較できる形式に変換します。
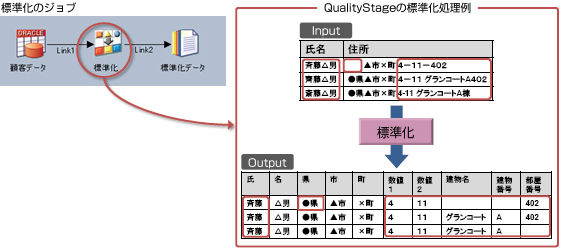
一般プログラムでは対応が難しい標準化の処理
標準化では、日本語の名前/住所などを標準化するためのアルゴリズムである「ルールセット」を各種提供。また、お客様のデータがルールセットで正しく標準化されたかをレポートする機能を提供します。
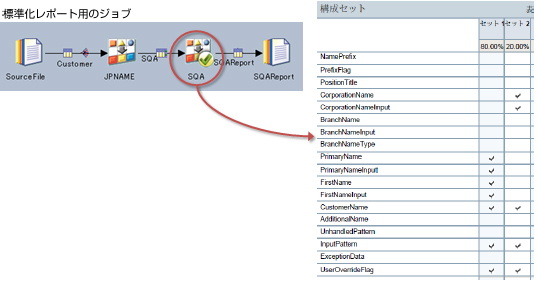
標準化結果の分析を実施
標準化のルールセットを適用した結果、お客様の実データが、正しく標準化されているかを確認できます。
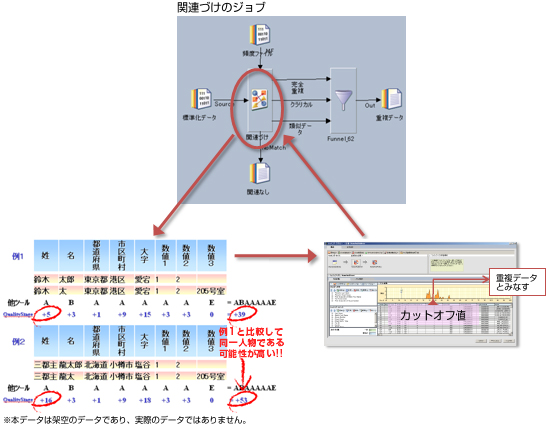
データの類似性を定量化し得点をつけ、高得点のデータを重複データとして関連づけます。 高得点のデータを重複データとみなすためのカットオフ値を設定できます。
データ類似性を定量化
比較対象の項目を選択。ウェイト比較法を用いて、データの類似性に得点をつける。
重複データの判断
重複データと判断できる高得点のデータにカットオフ(足切り)値をつける。実データの得点分布を視覚的に確認できるマッチングデザイナを提供。
重複データの特定後、どのデータを残すかの選定を行うための柔軟なルールを設定できます。
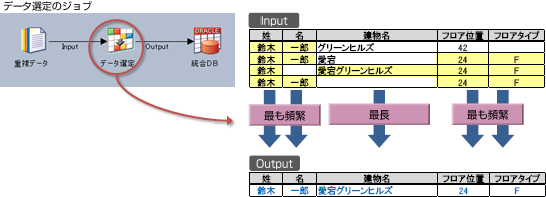
選定ルールを柔軟に設定