株式会社日立製作所は、このたび、多様なデータの活用を容易にするデータレイクハウス向けに進化した、超高速データベースエンジン「Hitachi Advanced Database(HADB)」の最新版Version6を10月1日から提供開始します。
具体的には、データレイクとして一般的に利用されるAmazon S3*1などのオブジェクトストレージ上の各種データ分析や生成AIの学習などに用いられるオープンテーブルフォーマット*2のデータを、HADBからSQLで直接検索できるようになりました。これにより、データ分析担当者は、データレイク内で分析対象となるデータの事前の加工やHADBへの取り込み作業が不要となり、HADB内のデータと合わせた横断的な検索・分析が可能となります。例えば、新サービス創出に向け、さまざまなデータを組み合わせて多角的に分析でき、サービスや取引履歴の分析業務の効率化が図れます。また、生成AIを業務に活用する際にも、データレイク内のデータ検索をすばやく行えるため、大量の学習データを早く整備でき、生成AIの学習効率の向上にもつながります。
また、HADBが備える非順序型実行原理による並列処理により、一般的に、オブジェクトストレージがブロックストレージに比べてデータの読み出し速度が遅いという点をカバーする高速なデータ検索が可能です。これにより、データ保管コストの低いオブジェクトストレージを利用しながらも、データウェアハウス水準の高速なデータ分析を実現できます。
さらに、一般的なクラウドサービスは検索データ量に応じた従量課金であるのに対し、HADB最新版では、従来のデータ容量ベースのライセンスに加え、データレイク上のデータを容量制限なく定額で検索できる新しいライセンスも選択できます。これらにより、データ保管コストの最適化にも寄与します。
なお、日立では、2025年度中に、オンプレミス環境や拠点ごとのデータレイクに適したAmazon S3互換オブジェクトストレージ「Hitachi Virtual Storage Platform One Object」を提供開始予定です。これにより、HADBのオンプレミス向けデータレイクソリューションの強化を進めるとともに、データレイク検索のさらなる高度化や今後のAI技術の進化を見据え、ベクトルデータやグラフ構造など、データの意味や属性まで考慮した類似検索技術への対応も行うなどHADBの機能強化を図っていきます。これらの取り組みにより、HADBの高速処理能力をさまざまな分野で活用し、企業のDXの加速を支援していきます。
詳しくは、下記のお知らせをご確認ください。
Hitachi Advanced Database Version6の製品説明資料は下記をご確認ください。
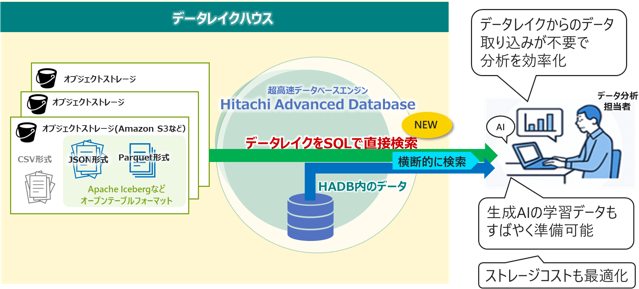
HADB Version6の利用イメージ
