Hitachi Advanced Databaseでは、同一表に対してデータ検索処理と並行してデータ格納処理の同時実行を実現する、バックグラウンドインポート機能をサポートしています。バックグラウンドインポートは、「チャンク*」単位でデータをインポートします。
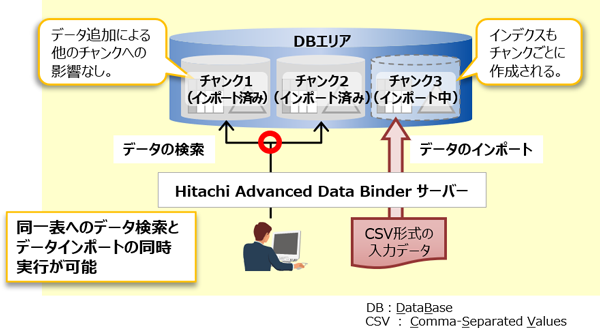
同一表へのデータ検索とデータインポートの同時実行が可能
以下のようにデータを取り込む頻度が高い場面でも、バックグラウンドインポートを適用し、検索処理を継続できます。
Hitachi Advanced Database では、データ検索ができる状態のまま、データを圧縮してファイルに出力(アーカイブ)することができます。このデータのアーカイブはチャンク*単位で実行しますが、この機能をチャンクアーカイブと言います。
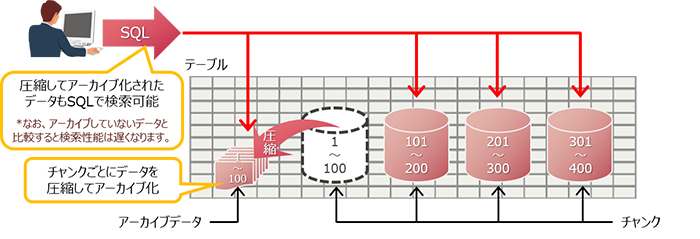
データのチャンクアーカイブ化とデータ検索
以下のような場面で、チャンクアーカイブが適用できます。
データのインポート後、1年以上経ち、使用頻度が低くなったデータはアーカイブします。その後データの保存期間が終了後は削除します。
「チャンクアーカイブ」により、検索頻度が低くなったチャンクを圧縮してデータベースの使用容量を削減することで、データのライフサイクルを意識した運用が可能になります。また、データを長期間保管するために必要なストレージのコストが削減できます。
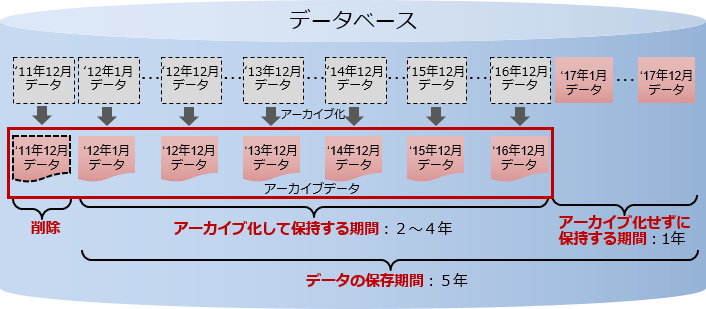
チャンクアーカイブによるデータのライフサイクル管理
Hitachi Advanced Databaseでは、同じ列のデータをディスク上に連続して格納するカラムストアに対応しています。ローストアとカラムストアを表定義時に選択できるため、データの用途に合わせた格納形式にできます。

ローストアとカラムストアの違いについて
カラムストアによる格納形式を選択した場合の適用効果についてご説明します。
カラムストアは集計項目のデータだけにアクセスしてディスクへのアクセス量を削減し、大量のデータの集計業務を高速化することで、分析結果をビジネスの現場で素早く活用できます。
また、Hitachi Advanced Databaseでは、チャンク*1およびレンジインデクス*2を活用することで、特定の月に絞り込んだ集計業務などの部分検索も高速に処理できます。
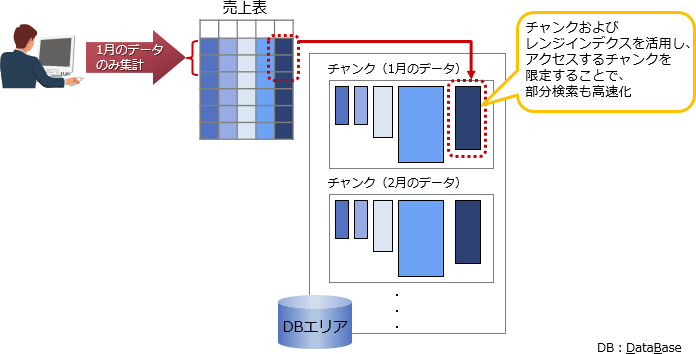
不必要なアクセスはスキップして集計処理を高速化
データの傾向を分析し、複数の圧縮アルゴリズムの中から最適な圧縮方法を自動的に採用します。ローストアのおよそ1/4~1/20にデータを圧縮できます*。
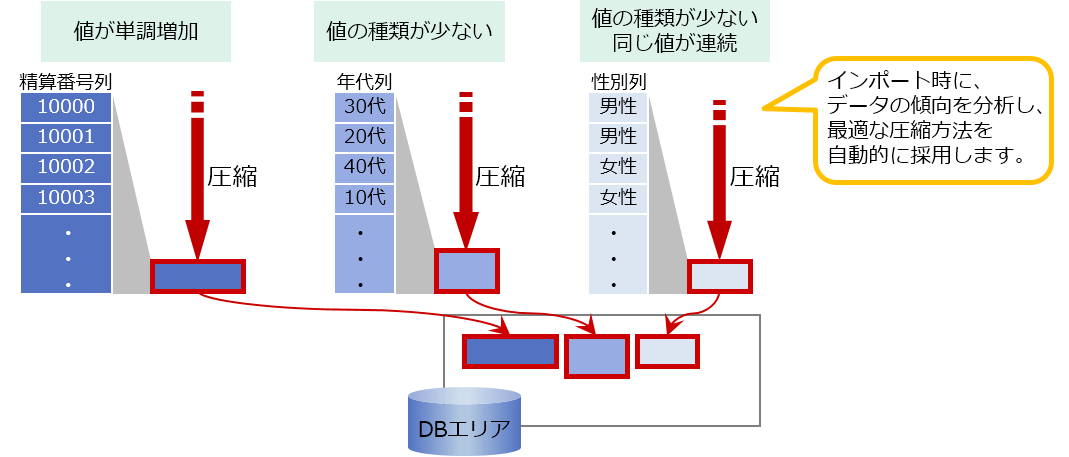
最適な圧縮方法を自動的に採用してデータ容量を削減
Hitachi Advanced Databaseでは、外部のデータレイクとして使用されるオブジェクトストレージに格納したオブジェクトやApache Icebergテーブルに対して、データベースにデータをインポートすることなく、SQLによる直接アクセスが可能な外部表に対応しています。外部表は、データベース上の表と同様の扱いであるため、直接検索のほか、データベース上の表に格納されたデータとの結合や横断検索が可能です。
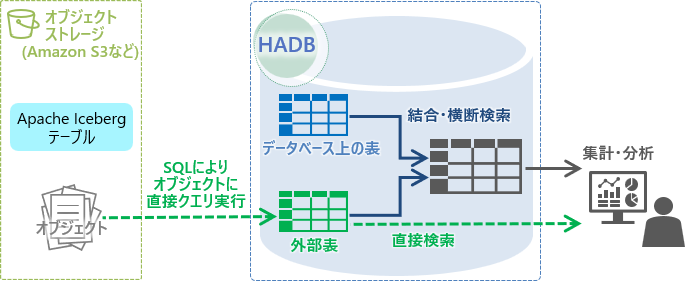
外部表を利用したオブジェクトへの直接検索とデータベース上の表との横断検索
データベースへのインポートが不要で、SQLによる直接処理が可能な点から、外部のデータレイク上のデータに対する仮説検証など、分析の準備に掛かる工数を削減します。また、外部のデータレイク上のデータとHitachi Advanced Database内部のデータとの横断検索が可能な点から、データレイク上に保管している過去データなどとの突合せが容易になります。これらにより、データ分析を効率化し、よりアドホックな分析を実現可能にします。
さらに、業務で使用するデータのうち、利用頻度が低いデータを保管コストが安価なオブジェクトストレージに格納し、利用頻度が高く、より高速な検索が求められるデータをHitachi Advanced Databaseに格納することにより、ストレージコストの最適化が可能になります。
