

金融系、公共系などの大規模システムのリプレースでは、上流工程で現行システムの仕様把握が欠かせません。長年使用されてきたシステムの把握は、担当者や有識者の経験・知識に依存しがちで、質、量ともに十分な調査が困難でした。
「情報システムスキャナ」は、ソースコードやDBデータ、ログを分析し、リプレースに必要な情報を自動出力する技術。迅速かつ漏れのない仕様把握を支援し、高品質なシステムのリプレースを実現します。
(2016年8月2日 公開)
大島システムから直接取得できるデータを読み込み、システムや業務に関する情報を自動出力する技術です。まず、システムのソースコードやDBデータ、ログをそれぞれ解析エンジンで分析します。そして、その結果を組み合わせて、業務フロー図、画面遷移図、ロジック決定表など、システムのリプレースに必要な仕様書を出力します。図1に示すとおり、「情報システムスキャナ」は、業務フロー再生、画面仕様再生、ロジック仕様再生、DB仕様再生の四つの要素技術で構成されています。
図1 情報システムスキャナの仕組み
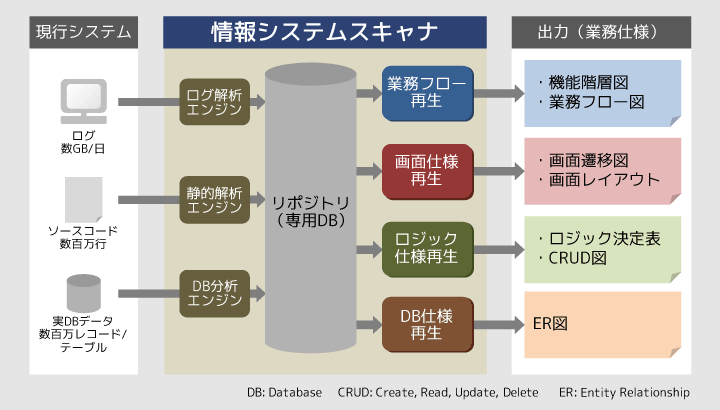
野尻すごく簡単に言ってしまうと、人の記憶には頼らずに、システムの仕様や業務の流れを浮き彫りにする技術です。詳しい人から話を聞けば、システムや業務について、ある程度わかります。でも、人の記憶にはあいまいなところがありますし、事実と主観が混ざってしまっていて、実態把握としては十分ではないこともあります。「情報システムスキャナ」は、すでにシステムにあるものと、いまシステムからとれるもの…具体的には、ソースコードと実DBデータ、ログだけを入力情報としているため、出力情報は主観を排除したエビデンスとして有効です。
大島ここ15~20年ぐらい、金融系や公共系の大規模なシステムでは、一から構築するよりも、現行のシステムをリプレースして、一部分だけ新機能を追加するケースが多くなっています。お客さまからは「現行のシステムと同じように実装してください」とご要望をいただくのですが、システムを作ったのが10~15年前だと、機能や実装方式を調べるのに大変な手間と時間が掛かります。現行システムの把握に時間が掛かりすぎてしまうと、次期システムの新機能の検討が十分にできないという問題もあります。調査が不十分なまま設計、実装してしまい、下流のテスト工程で機能の不足が発覚すると、大幅な手戻りになってしまいます。
野尻最近は、「新しいビジネスのためには、機能刷新のサイクルをもっと速くしていかないと」と考えているお客さまも多くいらっしゃいます。日立としても、このようなニーズに技術で応える必要がありました。
図2 情報システムスキャナの目的
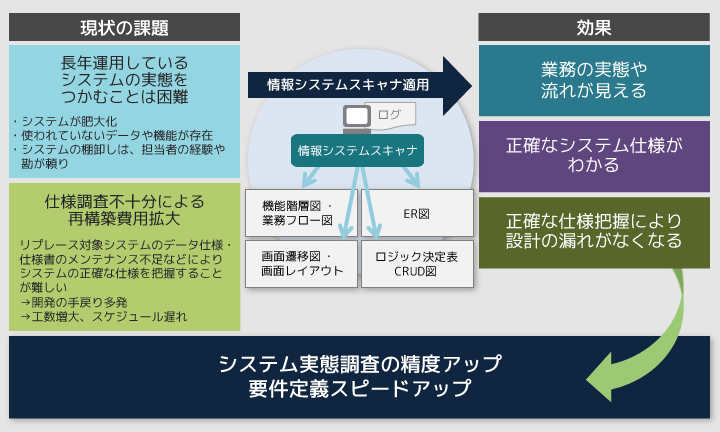
野尻出力情報は、システム開発者ではなくても、業務に詳しい人ならある程度わかる形になっています。たとえ事実だとしても、100万行のログをそのままお客さまにお見せしたら、それが何を示すのがご理解いただけませんよね。「情報システムスキャナ」の出力情報は、事実でありつつ、理解しやすい形になるように味付けされているんです。
大島この技術を使うと、システムの仕様や業務の流れだけでなく、システムの利用実態も明らかになります。お客さまと次期システムの仕様を議論するときに、「この機能はほとんど使われていませんよ」という根拠を示すことができるので、システムの肥大化防止にも役立ちます。
大島以前から、要素技術単体では研究していましたが、これらを組み合わせて業務仕様の出力まで持っていくことができるか、トライアンドエラーを始めたのは3年前です。ずいぶん大きなプロジェクトとして立ち上がったので不安もありましたが、技術を組み合わせることで出力の精度は上がるはず、何か新しいものが出るだろう、と期待していました。
野尻わたしは、提案段階でプロジェクトにかかわっていたものの、すぐ別の研究に入るためプロジェクトを離れることになりました。あれからどうなったのだろうと思いつつ、プロジェクトの2年目に戻ってきたら、1年の間にすごい成果が出ていて驚きました。このペースを落とさないようにしなければ…わたしに何ができるだろう、という気持ちで取り組みました。
大島野尻さんが合流した2年目からは、業務フロー再生、画面仕様再生、ロジック仕様再生、DB仕様再生の四つの要素技術のうち、わたしがDB仕様再生、野尻さんがロジック仕様再生、という分担になりました。

大島DB仕様再生では、DBにどのような傾向のデータが入っているのかわかるようにしました。長期間システムを運用していると、システム開発時には存在しなかった新しい仕様みたいなものが発生します。従業員コードを例に挙げると、通常は8けたの数字を入力するところで、Zの8けた(ZZZZZZZZ)だったらオールマイティで何でも通過する、なんてことも。このような仕様はシステム開発時に作成した設計書を調査しても検出できません。そこで、実DBデータを統計分析し、DBのカラムのフォーマットや特異値を自動で抽出できるようにしました。この技術によって、従業員コードの例であれば、フォーマットは数値8けたであっても、ZZZZZZZZという特異値が存在することを自動で検出できるようになります。
野尻ロジック仕様再生は、「業務ルール」をソースコードから抽出することを最終ゴールとしました。業務ルールというのは、例えば、入力した金額が100万円以上だったら警告メッセージを出す、といった条件のことです。また、業務と画面、業務とDBといった要素をつないでいるのがロジックです。そこで、ロジックが具体的にどの要素とどの要素をつないでいるのか明確にすることもめざしました。キーワードになるのが「プログラムスライシング」です。
野尻ソースコードはだいたい、たくさんの部品に分かれています。ある部品が、ユーザーが入力した情報を処理して、次の部品に投げて、処理して、また次に投げて…というふうに受け渡していく。この処理の受け渡しを追いかけるために、プログラムスライシングの考え方を取り入れました。特定のデータに関連するプログラムを部品から切り出していく、まさにスライスするんです。このプログラムのこのデータのここだけ、ここのプログラムのここだけ、というのをぱぱぱっと切って、頭からしっぽまでつなげる。
画面でデータを入力するのを頭、DBに収まるところをしっぽとしてプログラムスライシングをかけると、通過した条件が全部出てきます。これだけ見れば、ほかの余計なところを見なくてもロジックを抽出できる。その業務で使う画面やデータも明らかになるので、ロジックがつないでいる関係性をきっちりと追いかけることができました。
大島研究だと入力情報が全部そろっている前提で進めますが、実際の現場はそうとは限りません。システムの作り方によっては取得できない情報もあります。しかし、全部そろわないと分析できないのでは、現場で使ってもらえませんので、入力情報に不完全な部分があっても相応の結果が得られるよう、入力情報の種類や量で場合分けをしました。ここまで入力情報がそろえばこのくらいの精度、これがないとこの部分は類推になるのであやしい、というように。条件の制約がある中で、業務を理解するために何をどの程度の精度で出せるか考えるところが大変でした。
野尻プロジェクトの2年目に「ユーザー会」という組織を立ち上げました。実際にこの技術を使っていくことになるであろう事業部や関連会社の方に月1回程度集まってもらい、進ちょく報告とビジネス面でのニーズの吸い上げをしています。事業部横断、月1回のペースでこのような取り組みをしているのはめずらしいかもしれません。プロジェクト開始から1年でずいぶん成果が上がったので、そのまま置いておくのはもったいない、しっかりビジネスにしていこう、ということで始まりました。現在も継続しています。
大島お客さまからは、日立の最新技術をご紹介する場で、「塩漬けシステムを何とかしたいと思っている」「3年前の更改の際に欲しかった」など、好意的な意見を多くいただきました。
社内ですと、評価用に使ったシステムの開発部署に分析結果をフィードバックしたところ、設計書や知識では知り得なかった実態が抽出されていてうれしい、と好感触でした。ビジネス的な観点でも、調査の抜け漏れによる手戻りの防止、という費用面での効果が期待できそうです。

野尻「情報システムスキャナ」を次に控える設計のツールにつなげていくというのが、大きなところかなと思っています。現時点で自動でできるのは仕様書の出力までです。出力した仕様書は人の目で確認する必要があります。出力情報をそのまま設計ツールの入力情報として使えるようにするには、もう1段階、情報の追加が必要になってきます。
あとは、まだ出力情報にノイズが多いので、もう少し減らしたいですね。例えば、機械学習の知見を取り入れて、コンピューターの能力をフルに使ってさらにデータを刈り込めると、ノイズが減らせて、重要な情報の漏れもなくなるのではないかと思っています。
大島入社したときから一貫して、システムのよりよいアーキテクチャ作りをしていきたい、という思いで研究開発してきました。長く使われてきた現行システムを流用する部分と、金融系で盛り上がっているFintechやブロックチェーンなどを活用した新規で開発する部分をうまく連携させていく、新しいアーキテクチャを考えていけたら、と思います。
野尻わたしは、これまではどうしたらソフトウェアを簡単に速く作れるだろうか、ということを中心に研究してきましたが、最近はもう少し大きな、"ホワイトカラーの生産性"みたいなものにも自分の研究を広げていきたいなと思っています。雑用と呼ばれることは機械にやってほしいな、と思いますし(笑)。人工知能も楽しみな分野です。
ただ一方で、機械を100%信じる世界ではなくなってくるな、とも思っています。いまは、機械がしたことならなんでも100%正しいことを期待して、実際そうなっているかは別として「機械は常に正確であるべし」と思われている方も多いと思うんです。わたしもですが(笑)。でもこれからはそうじゃない。機械も人と同じで間違うこともあるという前提で、機械がしたことをわたしたちが評価して上手に付き合っていくことが、次の段階の生産性向上に必要だと思っています。まだ先の話かもしれませんが、そういうことに興味がありますね。
