Hadoop連携
IT企業において、Hadoopを活用したデータ統合の際にはさまざまな課題が伴います。最新テクノロジーのスキルセットを獲得し、最適な開発者を見つけ、Hadoopを既存の業務システムおよびデータウェアハウスに効果的に連携させなければなりません。
Pentahoの直感的かつ強力な基盤は、これらの課題に正面から取り組むことを目的として構築されており、導入することで、生産性の向上や収益化までの期間短縮を実現できます。さらに、複雑なデータ変換の管理や、データパイプラインの一部としてHadoopおよびSparkを運用できるため、信頼性の高い分析結果を提供できるようになります。
使いやすく強力なHadoopデータ統合
従来のビッグデータ統合ツールでは、管理機能やパフォーマンスの面で不十分な場合もあり、結果的にHadoopから遠ざかっているユーザーもいます。コード生成のアプローチについては、手作業でのコーディングに依存していることが多いため、ツールの導入には高い障壁があります。Pentahoは、設計者やアナリスト、そしてHadoop管理者に対して、ビジネスを成功に導くために必要な俊敏性とパワーを兼ね備えた機能を適切に組み合わせて提供します。
- 直感的なビジュアルインターフェイスにより、Hadoopのデータをリレーショナルデータベース、NoSQLストア、企業アプリケーションなどのあらゆるソースとの統合・ブレンドが可能
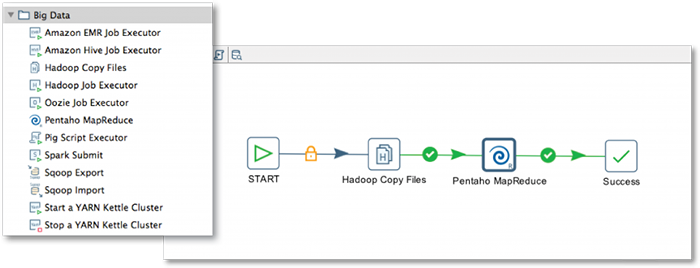
- デザインツールにより、手作業でのコーディングよりもすばやくMapReduceジョブの設計が可能
- MapReduceへのネイティブ統合により、Hadoopのスケーリングに合わせて、クラスター内での複雑なデータ変換・ブレンドが実行可能
- Spark SQL接続、各種Sparkアプリケーションのオーケストレーション、およびKafka、YARN、Oozie、Sqoopとの互換性など、Hadoopエコシステムと密接に統合
- 何百、何千もの多様かつ変化するデータソースを自動的にHadoopに収集し、処理できるように準備することで、プロセスを加速化
- Cloudera、Hortonworks、Amazon EMR、およびMapRなどの主要Hadoopディストリビューションのサポートにより、Hadoopプラットフォーム間でのジョブの移植や変換が可能
ビジネス成果につながるオンデマンドのビッグデータ分析
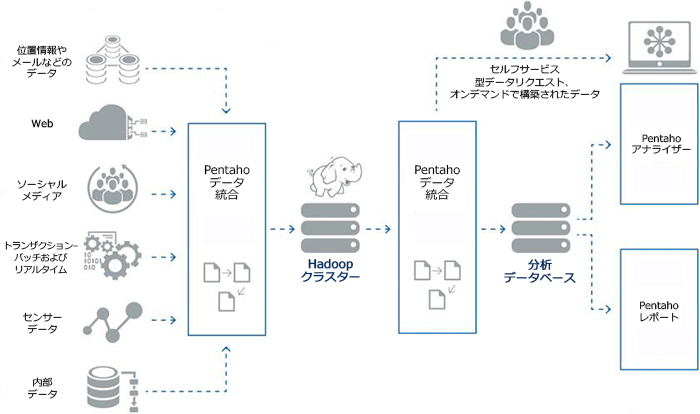
Hadoopを導入することで、まずデータインフラ費用の節約とパフォーマンスの改善を実現できます。さらに、導入後のデータ分析、またそこから得られる情報は、画期的な顧客体験や実際の売上増大につながっていきますが、実際には、生データを分析情報に変換するプロセス全体を熟知していないと、このような効果を得るのは難しいのです。PentahoとHadoopを組み合わせることにより、ビッグデータのパイプライン管理が可能となり、優れた業務成果を生み出しています。
- 大規模ユーザー向けに統制されたセルフサービス分析など、Hadoopからオンデマンドデータセットを提供するためのソリューションアプローチ
- HiveやImpala、さらにVerticaやRedshiftなどの分析データベースへの接続を含む、データの可視化、レポート、およびアドホック分析といった一連の作業が可能
- 重要な業務アプリケーションに分析機能をシームレスに組み込むことができるため、顧客およびパートナー企業のデータの収益化が可能
- RやWekaによる予測モデルをデータフローに取り込み、データの準備時間を最小限にしつつ実用的な結果につなげていくことが可能
アーキテクチャの例