ビッグデータ時代のデータ分析で、成功・失敗をわけるものは何か。
![]()
![]()
データの下準備ができたら、ようやく分析が始まる。 ここで、ひとつ重要なポイントがある。データ分析とは、一度やったら終了ではなく、繰り返し行うものだということである。「別の観点で分析したいから新しいデータを提供して」といったことが、繰り返し起こるのがデータ分析であり、そのたびに新たなデータに対する下準備が必要となる。つまり、「データ分析」と「データの下準備」は反復プロセスになっている。しかし、分析軸を変えるたびに下準備を手作業でやっていては、あまりに手間がかかるし、下準備用のプログラムをそのつど開発するのは多大な工数がかかるであろう。こういった背景から反復プロセスが継続できず、データ分析がうまくいかない原因のひとつとなっている。
なぜ失敗するのか
データの下準備や分析をデータサイエンティストに頼んでいる企業の場合、欲しい分析結果を現場がもらうまでに時間がかかることがよくある。データサイエンティストは他の業務と掛け持ちで作業しているケースが多いため、タイムリーに分析結果を手に入れるのは難しいといった実態があるのだ。そうなると、情報の鮮度が落ちてしまうという弊害も発生する。
更新が頻繁に繰り返されるビッグデータは、すぐに情報が古くなってしまうため分析に時間を掛けていられない。従来のデータ活用と比べて、情報に求められる鮮度が異なるのだ。つまり、高い頻度で分析してこそ価値があるのが、ビッグデータの利活用なのである。
総務省「ビッグデータの流通量の推計及びビッグデータの活用実態に関する調査研究」(平成27年)によると、ビッグデータの分析の頻度が1日未満(1日に1回以上分析をしている)という企業は、高い割合で分析の効果を得ている。全体を見ても、効果を得ている企業の過半数は、1か月未満の頻度で分析を行っている。
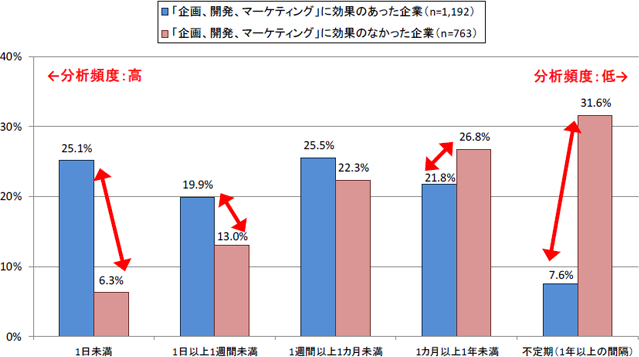
図の出典:総務省「ビッグデータの流通量の推計及びビッグデータの活用実態に関する調査研究」図表4-21
この結果からもわかるように、高い頻度で分析を行うことがビッグデータ利活用においては重要である。近年では、セルフサービスBIの普及に見られるように、現場や各部門で目的に沿ってデータ分析をして、ビジネスの変化に柔軟に対応したいというニーズが増えている。こうした動きに乗り遅れないよう、現場に迅速に分析用のデータを供給できる環境を整備し、データの下準備とデータ分析を柔軟に、かつ高い頻度で反復できる仕組みを整えることが、非常に重要になってきている。
データパイプラインは、優れたデータ分析を可能とする理想的な構想である。しかし、見よう見まねで構築しても決して成功はしない。次の3つの条件を満たしたデータパイプラインを構築することが、データ分析の成功へとつながる。
ホワイトペーパー「8項目の必須チェックリスト」は、データパイプラインの本格的な構築にあたって、データ接続やデータ準備、そのほかデータパイプラインの効率的な管理などに関する注意点や、考慮すべき点を詳細にまとめた情報となっている。
