![]()
データ統合の開発基盤(ETLツール) DataStage:サーバージョブとパラレルジョブの違いについて
データの抽出/加工/格納の一連の処理の単位をジョブと呼びます。
DataStageのジョブには、サーバージョブとパラレルジョブの2種類があります。
- ※
- 開発元方針でサーバジョブのエンハンスは行っていません。このため、サーバジョブは既存資産の稼動のみとなり、新規作成はできません。
サーバージョブでは、基本的には1つのジョブを1つの実行プロセスで処理します。
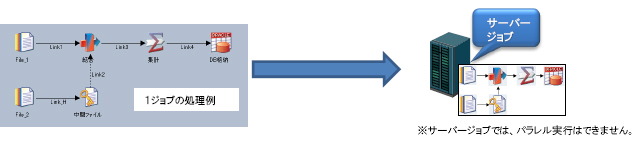
【サーバージョブエンジンによるジョブ実行処理例】
パラレルジョブでは、1つのジョブを実行時に指定するノード数に従ってデータを分割し、複数の実行プロセスで処理します。
サーバージョブに対して次のような特長があります。
- 大規模のデータを高速に処理するためのパラレル実行を容易に実現。
- 大規模データを自動的に分割し、パラレル実行を実現。マルチプロセッサをフルに活用した高速処理が可能。
- パラレル実行の並列数は実行時に指定。ジョブを変更することなく、並列数を柔軟に変更可能。
- DBのパーティション表と連携し、分割データを引き継ぐことが可能。データの抽出・ロード処理とデータ加工処理でデータの再分割が不要。
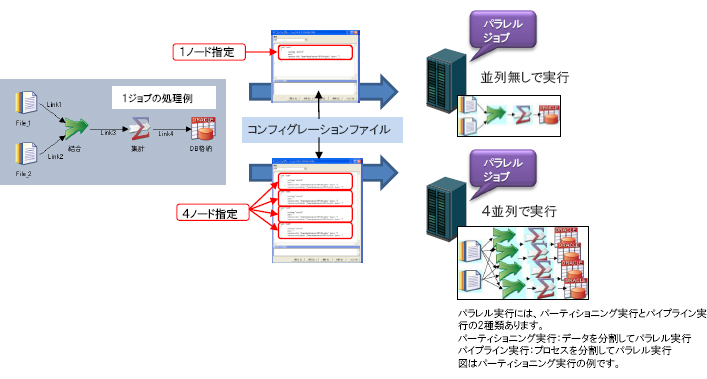
【パラレルジョブエンジンによるジョブ実行処理例】